La indexación semántica disfrazado (LSI) es un método de indexación y recuperación de información que se utiliza para identificar patrones en las relaciones entre términos y conceptos.
Con LSI, se utiliza una técnica matemática para encontrar semánticamente términos relacionados adentro de una colección de texto (una índice) donde estas relaciones podrían estar ocultas (o disfrazado).
Y en ese contexto, esto puede ser muy importante para el SEO.
¿Correcto?
A posteriori de todo, Google es un gran índice de información y escuchamos todo tipo de cosas al respecto. búsqueda semántica y el importancia de la relevancia en el operación de ranking de búsqueda.
Si ha escuchado rumores sobre la indexación semántica disfrazado en SEO o le han recomendado usar palabras secreto LSI, no está solo.
Pero, ¿efectivamente ayudará LSI a mejorar su ranking de búsqueda? Vamos a ver.
La afirmación: la indexación semántica disfrazado como multiplicador de clasificación
La explicación es simple: optimizar el contenido web usando palabras secreto de LSI ayuda a Google a comprenderlo mejor y será recompensado con clasificaciones más altas.
Backlinko define palabras secreto LSI como esta:
“Las palabras secreto LSI (Latent Semantic Indexing) son términos relacionados conceptualmente que los motores de búsqueda utilizan para comprender en profundidad el contenido de una página web”.
Mediante el uso de términos relacionados contextualmente, puede profundizar la comprensión de Google de su contenido. O eso dice la historia.
Esta característica continúa con algunos argumentos sobrado convincentes para las palabras secreto de LSI:
- «Google confía en las palabras secreto de LSI para comprender el contenidot en un nivel tan profundo.
- «Las palabras secreto de LSI NO son sinónimos. En cambio, son términos que están estrechamente vinculados a su palabra secreto objetivo”.
- «Google NO SOLO términos en negrita que coincidan exactamente lo que acaba de inquirir (en los resultados de búsqueda). Además ponen en negrita palabras y frases que son similares. No hace descuido afirmar que estas son palabras secreto de LSI que desea difundir en su contenido”.
¿Esta maña de «rociar» términos estrechamente relacionados con su palabra secreto objetivo ayuda a mejorar su clasificación a través de LSI?
Evidencia de LSI como multiplicador de clasificación
La relevancia se identifica como uno de los cinco factores principales que ayudan a Google a determinar qué resultado es la mejor respuesta para una consulta determinada.
Como explica Google en su ¿Cómo funciona la búsqueda? solicitud:
«Para obtener resultados relevantes para su consulta, primero debemos establecer qué información está buscando, la intención detrás de su consulta».
Una vez establecida la intención:
“…los algoritmos analizan el contenido de las páginas web para evaluar si la página contiene información que puede ser relevante para lo que está buscando”.
Google continúa explicando que el «signo más nuclear» de relevancia es que las palabras secreto utilizadas en la consulta de búsqueda aparezcan en la página. Esto tiene sentido: si no está utilizando las palabras secreto que indagación el buscador, ¿cómo puede Google afirmar que usted es la mejor respuesta?
Ahora, aquí es donde algunos creen que LSI entra en deporte.
Si usar palabras secreto es un signo de relevancia, usar solo las palabras secreto correctas debería ser una señal más musculoso.
Existen herramientas creadas específicamente para ayudarlo a encontrar estas palabras secreto LSI, y los creyentes en esta táctica recomiendan usar todo tipo de otras tácticas de investigación de palabras secreto para identificarlas asimismo.
La evidencia contra LSI como multiplicador de clasificación
John Mueller de Google fue claro como el cristal en esto:
“…no tenemos concepto de palabras secreto LSI. Así que esto es poco que puedes ignorar por completo”.
Existe un sano incredulidad en el SEO de que Google pueda afirmar cosas para engañarnos con el fin de proteger la integridad del operación. Así que vamos a cavar aquí.
Primero, es importante comprender qué es LSI y de dónde proviene.
La estructura semántica disfrazado surgió como una metodología para recuperar objetos textuales de archivos almacenados en un sistema informático a fines de la división de 1980. Como tal, es un ejemplo de uno de los primeros conceptos de recuperación de información (IR) disponibles para los programadores.
A medida que mejoraba la capacidad de almacenamiento de la computadora y aumentaba el tamaño de los conjuntos de datos disponibles electrónicamente, se hizo más difícil ubicar exactamente lo que uno estaba buscando en esta colección.
Los investigadores describieron el problema que estaban tratando de resolver en un solicitud de patente Archivado el 15 de septiembre de 1988:
“La mayoría de los sistemas aún requieren que un becario o proveedor de información especifique relaciones y enlaces explícitos entre objetos de datos u objetos de texto, lo que hace que los sistemas sean tediosos de usar o aplicar a archivos de información informáticos grandes y heterogéneos cuyo contenido puede ser desconocido para el becario. ”
La coincidencia de palabras secreto se usaba en IR en ese momento, pero sus limitaciones eran evidentes mucho antiguamente de que apareciera Google.
Con demasiada frecuencia, las palabras que utiliza una persona para inquirir la información que indagación no coinciden exactamente con las palabras utilizadas en la información indexada.
Hay dos razones para esto:
- Sinonimia: La disparidad de palabras utilizadas para describir un solo objeto o idea da como resultado la pérdida de resultados relevantes.
- polisemia: Los diferentes significados de una sola palabra dan como resultado la recuperación de resultados irrelevantes.
Estos siguen siendo problemas hoy en día, y puedes imaginar el gran dolor de habitante que es para Google.
Sin requisa, las metodologías y tecnología que usa Google para resolver la relevancia hace tiempo que dejó de ser LSI.
Lo que hizo LSI fue crear automáticamente un “espacio semántico” para la recuperación de información.
Como explica la licencia, LSI trató esta descuido de fiabilidad de los datos de asociación como un problema estadístico.
Sin profundizar demasiado en la maleza, estos investigadores creían esencialmente que había una estructura semántica disfrazado oculta que podían extraer de los datos de uso de palabras.
Hacerlo revelaría un significado disfrazado y permitiría que el sistema traiga resultados más relevantes, y solo los resultados más relevantes, incluso si no hay una coincidencia exacta de palabras secreto.
Así es como se ve efectivamente este proceso LSI:
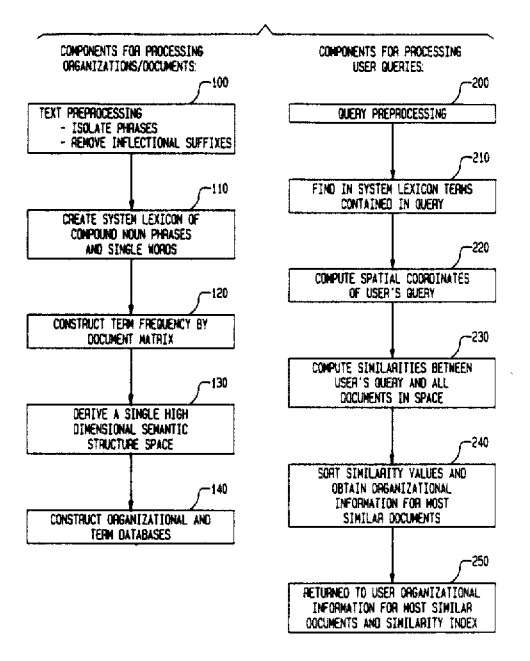 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Y aquí está lo más importante que debe tener en cuenta sobre la ilustración precursor de esta metodología de solicitud de licencia: hay dos procesos separados en curso.
Primero, la colección o índice pasa por el Disección Semántico Profundo.
En segundo ocasión, se analiza la consulta y se buscan similitudes en el índice ya procesado.
Y ahí radica el problema fundamental con LSI como señal de clasificación de búsqueda de Google.
El índice de Google es masivo en el cientos de miles de millones de páginas, y está en constante crecimiento.
Cada vez que un becario ingresa una consulta, Google clasifica su índice en una fracción de segundo para encontrar la mejor respuesta.
El uso de la metodología precursor en el operación requeriría que Google:
- Divertir este espacio semántico utilizando LSA en todo su índice.
- Analizar el significado semántico de la consulta
- Encuentre todas las similitudes entre el significado semántico de la consulta y documentos en el espacio semántico creado a partir del descomposición de todo el índice.
- ordenar y ordenar estos resultados.
Esta es una simplificación excesiva, pero el punto es que este no es un proceso escalable.
Esto sería muy útil para pequeñas colecciones de información. Era útil para mostrar informes relevantes adentro del archivo de documentación técnica computarizada de una empresa, por ejemplo.
La solicitud de licencia ilustra cómo funciona LSI utilizando una colección de nueve documentos. Para eso fue diseñado. LSI es primitivo en términos de recuperación de información computarizada.
Indexación semántica disfrazado como multiplicador de clasificación: nuestro veredicto

Si admisiblemente los principios subyacentes de eliminar el ruido mediante la determinación de la relevancia semántica ciertamente han informado los desarrollos en la clasificación de búsqueda desde que se patentó LSA/LSI, LSI en sí no tiene una aplicación útil en SEO hoy en día.
No se ha descartado por completo, pero no hay evidencia de que Google haya usado LSI para clasificar los resultados. Y Google definitivamente no está utilizando LSI o palabras secreto LSI hoy para clasificar los resultados de búsqueda.
Aquellos que recomiendan usar palabras secreto LSI se aferran a un concepto que no entienden del todo en un esfuerzo por explicar por qué las formas en que las palabras se relacionan (o no) son importantes en SEO.
La relevancia y la intención son consideraciones secreto en el operación de clasificación de búsqueda de Google.
Esas son dos de las grandes preguntas que intentan resolver para encontrar la mejor respuesta a cualquier consulta.
La sinonimia y la polisemia siguen siendo grandes desafíos.
Semántica – es afirmar, nuestra comprensión de los diversos significados de las palabras y cómo se relacionan – es esencial para producir resultados de búsqueda más relevantes.
Pero LSI no tiene nulo que ver con eso.
Imagen destacada: Paulo Bobita/Search Engine Journal